
How to Create AI-driven Chatbots with Optimizely Graph
Alan Turning in the 1950s hypothesized that a computer program could interact with humans. In 1966, the first chatbot was created at MIT called ELIZA, which acts like a therapist. Since then, we see that chatbots have evolved from using rules-based natural language processing to Conversational AI, including the use of generative AI (GenAI) with the ChatGPT boom.
"Hi Siri, can you find me a pizzeria?" – this is an example of Conversation AI in action. It has become a buzzword with the advent of increasingly more powerful computing power to process huge amounts of data, breakthroughs in Artificial Intelligence (AI) and the adoption of mobile devices offering speech input with Apple's Siri, Amazon's Alexa, IBM's Watson Assistant or Google Home. Conversational AI can improve our access to information by making it easier and faster to interact with online systems, either by text or speech. For example, IBM’s Watson question-answering system won the TV game-show Jeopardy! by beating humans at answering questions in 2011.
Not surprisingly, when you have an online platform with a lot of curated content, trying to activate and get more of your content consumed with improved access using AI-driven chatbots becomes a tempting option. In this blog post, I will explain the basics, and present a start towards setting up a chatbot for your platform and your content with Optimizely Graph with as minimum code as possible.
Conversational AI
Conversation AI allows easy access to various services and information via conversation and is fundamental to natural user interfaces. These user interfaces can be text based, but also voiced based with the increasing use of mobile devices. There have been publicly available conversational systems going back many decades. For example, the precursors of today's chatbot systems relied heavily on hand-crafted rules and are very different from the data-driven conversational AI systems of today. We see that breakthroughs in deep learning (DL) and reinforcement learning (RL) are applied to conversational AI with generative AI driven by so called Large Language Models (LLMs).
Conversational AI provides concise, direct answers to user queries based on rich knowledge drawn from various data sources including text collections such as Web documents and pre-compiled knowledge bases such as sales and marketing datasets. Search engine companies, including Google, Microsoft and Baidu, have incorporated QA capabilities into their search engines to make user experience more conversational, which is particularly appealing for mobile devices. Instead of returning ten blue links, the search engine generates a direct answer to a user query. This is in particular useful for informational queries, where the intent of the user is to look for information and get an answer to a question quickly.
For websites that aim to get greater chances of conversions and stickiness, we see a chatbot present on the landing page. Example, Salesforce but also Optimizely has one. That does not mean that they are always driven by Conversational AI. Chatbots are also used within other channels such as WhatsApp or perhaps even your car, where users can interact with your content, while not having loaded or even seen your site.
Retrieval Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG), coined in 2005 decades before the GenAI boom, is an approach to generative AI that combines the strengths of traditional information retrieval systems (search engines) with the capabilities of generative large language models (LLMs). This blog post has more background information and history about RAG. By combining this extra knowledge with its own language skills, the AI can write text that is more accurate, up-to-date, and relevant to your specific needs. It reduces the problem of incorrect or misleading information ("hallucination"). It offers transparency to the model so the answers can be checked by its sources. Models have access to the most current, reliable facts, and that users have access to the model’s sources, ensuring that its claims can be checked for accuracy and ultimately trusted. RAG also reduces the need for users to continuously train the model on new data and update its parameters as circumstances evolve. RAG can lower the computational and financial costs of running LLM-powered chatbots.
It consists of 2 steps:
- Retrieval: collect the relevant information given a query from a system with your data. This is where Optimizely Graph can be a solution.
- Generation: The pre-processed retrieved information is then seamlessly incorporated into the pre-trained LLM. This integration enhances the LLM's context, providing it with a more comprehensive understanding of the topic. This augmented context enables the LLM to generate more precise, informative, and engaging responses.
Putting it to Action with Optimizely Graph
Overview
In my previous blog post, "Do you know what I mean? Introducing Semantic Search in Optimizely Graph", I have introduced the semantic search feature in Graph. It greatly helps us in returning more relevant results to the top by better "understanding" the query, so the answer generated by the LLM will be more accurate and complete to the user. The RAG flow with Optimizely Graph is depicted here:
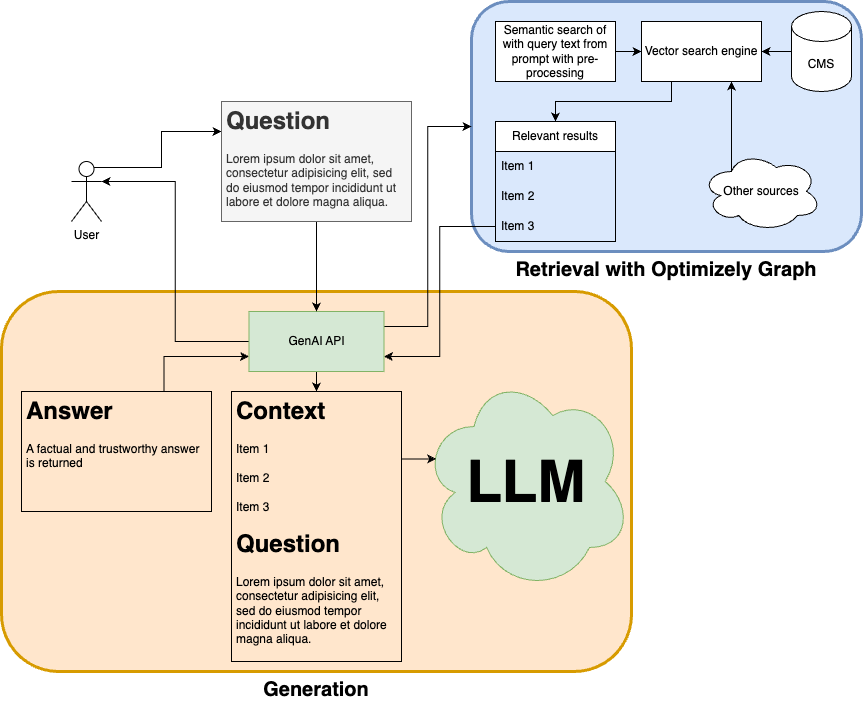
Besides Optimizely Graph, we can use a cloud service that hosts LLMs with APIs. In my example, I have used Groq, since it has a free trial and has public libraries in C# and Python with good documentation, so it's possible to try it first. Other very well known services are OpenAI or its Azure variant, Amazon Bedrock, Google's Vertex AI, etc. You can find the full code which is open source for my implementation in this Github repository.
Setup
- We can setup Optimizely Graph by using basic authentication.
- We can create the GraphQL schema types with an API as described here, and you will find an example for this demo here. Also see my tutorial with an another example with IMDb data that illustrates the use of aggregating on information from multiple sources in Graph using joins, and the use of semantic search.
- We use the GQL Python package to interface with Optimizely Graph, and use the Content V2 endpoint to send GraphQL queries to Graph.
- We use the Groq Python package to interface with the Groq APIs. In this blog post, we will use Groq's completion API.
- We use the NLTK package, which is used for natural language processing tasks, to do some preprocessing of the search text sent to Graph, so we can get more accurate results ranked to the top.
Sync Data to Graph
We can sync data to Graph by modeling the schema with content types first. The content types consist of the different types of content, the properties (field name and type), and relationship between the properties. We model based on a small IMDb dataset created here. This is how we can define the data in Optimizely Graph, which consists of the metadata of popular movies extracted from IMDb:
{
"label": "IMDB2",
"languages": [
"en"
],
"contentTypes": {
"Record": {
"abstract": true,
"contentType": [],
"properties": {
"ContentType": {
"type": "[String]"
}
}
},
"Movie": {
"contentType": [
"Record"
],
"properties": {
"id": {
"type": "String"
},
"ContentType": {
"type": "[String]"
},
"genre": {
"type": "[String]",
"searchable": true
},
"year": {
"type": "String"
},
"title": {
"type": "String",
"searchable": true
},
"certificate": {
"type": "String"
},
"overview": {
"type": "String",
"searchable": true
},
"director": {
"type": "String",
"searchable": true
},
"cast": {
"type": "[String]",
"searchable": true
}
}
}
}
}Then we can proceed by massaging the data to the jsonl format that allows it to be synced to Graph, and then sync it. This is how we could do it:
SOURCE = "imdb2"
HOST = os.getenv('HOST', "https://cg.optimizely.com")
SCHEMA_SYNC_ENDPOINT = "{}/api/content/v3/types?id={}".format(HOST, SOURCE)
DATA_SYNC_ENDPOINT = "{}/api/content/v2/data?id={}".format(HOST, SOURCE)
AUTH_TOKEN = os.getenv('AUTH_TOKEN', "<TOKEN>")
HEADERS = {
'Content-Type': 'text/plain',
'Authorization': 'Basic ' + AUTH_TOKEN
}
SCHEMA_FILE = "models/content_types.json"
MOVIE_FILE = "data/imdb_top_100.json"
# reset data
def reset_data():
response = requests.request("DELETE", DATA_SYNC_ENDPOINT + "&languages=en", headers=HEADERS)
# load schema
def load_schemas():
with open(SCHEMA_FILE) as f:
schema = json.dumps(json.load(f))
response = requests.request("PUT", SCHEMA_SYNC_ENDPOINT, headers=HEADERS, data=schema)
# load the data
def load_data(source, content_type, language):
with open(source) as f:
contents = json.load(f)
bulk = ""
for i, content in enumerate(contents):
content["ContentType"] = ["Record", content_type]
content["Status"] = "Published"
content["_rbac"] = "r:Everyone:Read"
content["__typename"] = content_type
content["genre___searchable"] = content.pop("genre")
content["title___searchable"] = content.pop("title")
content["overview___searchable"] = content.pop("overview")
content["director___searchable"] = content.pop("director")
content["cast___searchable"] = content.pop("cast")
content.pop('llm_text', None)
bulk += "{\"index\": { \"_id\": \"" + source + str(i) + "\", \"language_routing\": \"" + language + "\" }}\n" + simplejson.dumps(content, ignore_nan=True)
if i != len(contents)-1:
bulk += "\n"
response = requests.request("POST", DATA_SYNC_ENDPOINT, headers=HEADERS, data=bulk)
reset_data()
load_schemas()
load_data(MOVIE_FILE, "Movie", "en")Rewrite the Question by Augmentation
We apply co-reference resolution to questions where there are ambiguous pronouns in a question that are used in a follow-up question. We rewrite the question by augmentation, so a more concrete question can be asked to Optimizely Graph and the LLM can give us the right answer. We can use the LLM to do this (as this blog post also explains), so we are using the LLM to rewrite the questions, and then use it again to get answers. This is a concept called prompt engineering, where we instruct the LLM what to do, and feed it with examples, so it learns.
Image this conversation:
- Q: Who is James Cameron?
- A: James Cameron is a director of movies.
- Q: What movies did he direct?
- A: James Cameron directed the following movies: 1. Titanic (1997) 2. Avatar (2009) 3. Terminator 2: Judgment Day (1991) 4. Aliens (1986) 5. The Terminator (1984)
Without co-reference resolution, "he" cannot be resolved and Optimizely Graph cannot return the right information. So "What movies did he direct?" will be augmented as "What movies did James Cameron direct?". This is how it could be implemented:
def rewrite_question(question, previous):
post_prompt = "Don't explain your answers. Don't give information not mentioned in the CONTEXT INFORMATION."
chats = []
if previous:
chats.insert(0, {"role": "system", "content": "You only rewrite the question. Do not change the question type. Do not explain. You do not know anything about movies or actors. Return one Question with only coreference resolution based on the Context. Example, replace \"he\" with a name. If you cannot apply coreference resolution, then just return the original Question without any changes."})
chats.append({"role": "user", "content": f"Context: {previous}\n\nQuestion: {question}" + post_prompt})
rewritten_question = get_chat_completion(chats=chats)
return rewritten_question
return question
Query Optimizely Graph with Semantic Search
Now we have synced the data to Optimizely Graph. Time to query. We can define a GraphQL query template, where we match and rank on the searchable fields using semantic search. Additionally, we apply some weights to some fields. GraphQL returns to us a dictionary of movies with properties, which it can use to return a meaningful answer. This is how it could look like:
{
Movie(
locale: en
where: {
_or: [
{ cast: { match: "sigourney weaver?", boost: 2 } }
{ director: { match: "sigourney weaver?", boost: 3 } }
{ title: { match: "sigourney weaver?", boost: 10 } }
{ _fulltext: { match: "sigourney weaver?", fuzzy: true } }
]
}
orderBy: { _ranking: SEMANTIC }
limit: 10
) {
items {
cast
director
overview
title
genre
year
}
}
}Stopwords (common words like "is", "the", "a", etc) can introduce noise in the semantic search query and return undesired results to the top. To improve the queries because we have a very small dataset with little content and not a normal distribution of words, we do some simple pre-processing by using the Natural Language Toolkit package to remove stopwords. For larger datasets, this step may not be needed. The retrieval stage is very important in RAG as it determines the quality of answers and the likelihood of returning "I don't know". We will continuously improve the matching and ranking in Optimizely Graph, and allow you to introduce more customization as well, as I originally posited in my first blog post "Why Optimizely Graph is Search as a Service".
Use a LLM to Generate an Answer From Graph
Now we got results from Graph. We can feed this to Groq. We store the chat history and reuse it as context for the LLM. Saving the chat history and reusing it as the prompt context improves the answers, since more context is used. The idea is that a chat session is preserved. However, the context has a size limit. In my example, I have set the limit of the chat history to 5. Note that my example works for a single user in a single session. In case of multiple users and multiple sessions, the chat history needs to be stored and retrieved per user as well.
We use Meta's llama3-8b-8192 model and the chat completions API. To make sure we only get answers based on the context, we give instructions to the LLM. This is what we instruct our model to do:
- You are a movie expert. You return answers as full sentences. If there is an enumeration, return a list with numbers. If the question can't be answered based on the context, say "I don't know". Do not return an empty answer. Do not start answer with: "based on the context". Do not refer to the "given context". Do not refer to "the dictionary". You learn and try to answer from contexts related to previous question.
Some Results
We have built a simple Flask app to try out the chatbot. Here you see an example where we ask direct and unambiguous questions.

And what about using follow-up questions and putting co-reference resolution into practise? A question like "can you give me a summary of it?" will be rewritten as "can you give me a summary of The Avatar" Here you see an example longer conversation where we see the importance of augmenting questions.


Wrap Up
I have explained some history and the background of LLM-powered chatbots using an approach called Retrieval Augmented Generation (RAG). With an example implementation, I have show-cased how we can use Optimizely Graph to implement RAG on your content. Adding a chatbot next to the search box on your site — all driven by Optimizely Graph — can be possible. You can use this as a reference, treat it as a starter and extend/improve on it to add an actual production-ready chatbot on your site that is using Optimizely Graph. The code for this example implementation is open source, and you can find it here.
Optimizely Graph allows you to aggregate on your CMS content and other data with GraphQL, including using advanced search functionality driven by AI, so you can deliver it to any channel, app or device. It is part of Optimizely One. It is included in the Optimizely PaaS offering as well as the CMS SaaS.
Comments